Problem Description:
After IntelliJ idea is installed, the following errors will occur when submitting or updating and checking out code using SVN:
Cannot load supported formats: Cannot run program “svn”: CreateProcess error=2
The reason is that SVN uses the command-line tool. If there is no SVN command-line tool locally, an error will occur.
Solution:
1. Reinstall the SVN client
When installing the TortoiseSVN client, the command line client tools option must be selected. So Xiaobian quietly unloaded and then reinstalled. As shown in the figure:
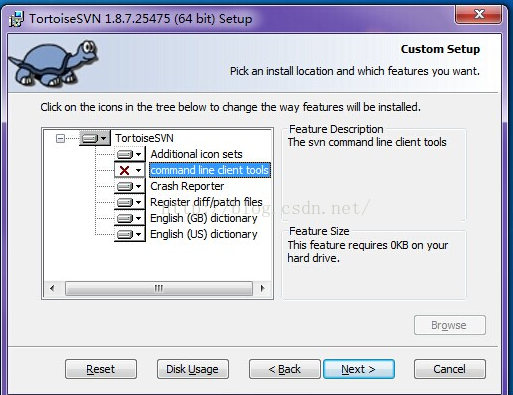
When installing the TortoiseSVN client, the command line client tools option must be selected. So Xiaobian quietly unloaded and then reinstalled.
As shown in the figure:
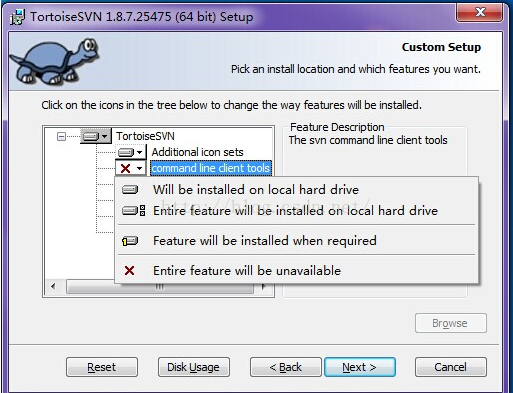
Then select the first item will be installed on local hard drive
2. Configure SVN in idea
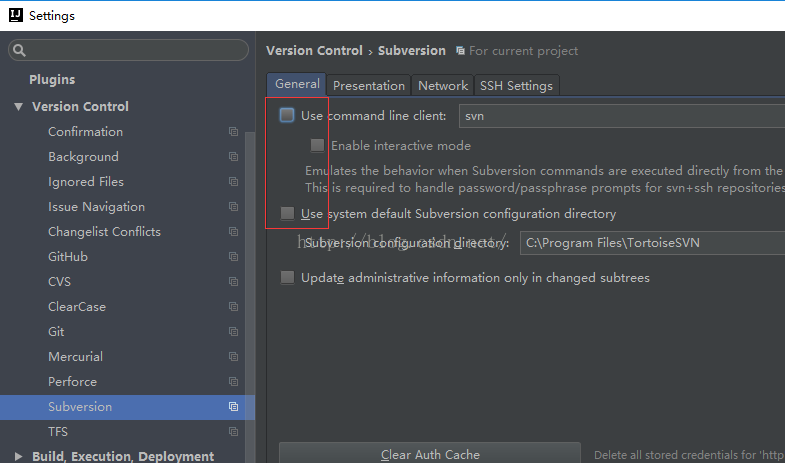
Remove the check mark from both check boxes.
Idea, which had been used for some time before, was deeply attracted by its cool black background, but it was never opened after going back. In fact, there are many basic functions that are not used well, which leads to digging such a big hole for yourself now. Since the pit fell in, you must fill it out, or you will fall in again.
Similar Posts:
- Solution to the error “can’t use subversion command line client: SVN” in idea
- Can’t use Subversion command line client: svn.
- Cannot load supported formats: Cannot run program “svn“: CreateProcess error=2
- [Solved] yarn Install Module Error:check python checking for Python executable “python2” in the PATH
- Intellij IDEA Golang Error: no Go files in D:\basic_tool\Go\src\gosvc
- Solving fastdfs in Windows Environment_ Client installation error, error: Microsoft Visual C + + 14.0 is required
- IDEA double click can’t open no response Issue [How to Solve]
- Error running ‘JeecgSystemApplication‘: Command line is too long. Shorten command line for JeecgSys
- [Solved] Error running ‘CableApplicationStart’: Command line is too long.
- Error running ‘JeecgSystemApplication’: Command line is too long. Shorten command line for JeecgSystemApplication or also for Spring Boot default configuration.